Advancing Text-to-Image Generation: A Comparative Study of StyleGAN-T and Stable Diffusion 3 under Neutrosophic Sets
Keywords:
Neutrosophic Sets; Uncertainty; Text-to-Image Generation; StyleGAN-T; DF-GAN; AttnGAN; BigGAN; Stable Diffusion 3; DALL·E 3; Midjourney v6; Imagen 2Transformer-based GAN; Diffusion Models; Text-to-Image Generation; Semantic Alignment, Image Quality Metrics.Abstract
Recent advances in generative models have revolutionized the technology employed
for image synthesis quite significantly, and two paradigms—GANs and diffusion-based
models—are leading the pack of innovation. This paper outlines an extensive comparison and
analysis of some of the best models across both paradigms, namely StyleGAN-T, DF-GAN,
AttnGAN, and BigGAN on the GAN side and Stable Diffusion 3 (SD3), DALL·E 3, Midjourney
v6, and Imagen 2 on the diffusion side.
We systematically inspect the architectural design, training protocols, text-conditioning
processes, and domain adaptability of each model, highlighting how they address text-to-image
generation challenges differently. Through qualitative and quantitative measurements—such as
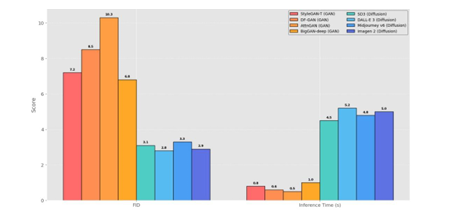
FID, CLIP Score, human preference surveys, and compositional accuracy, the work reveals
performance tradeoffs concerning speed, control, creativity, semantic alignment, and
photorealism. We use the Neutrosophic Set model to select the best model based on these
evaluation matrices. We have different scores for each model based on evaluation matrices. So,
the neutrosophic set is used to overcome the uncertainty information. We use the COPRAS
method to rank the models and select the best one based on the evaluation matrix weights.
Downloads
Downloads
Published
Issue
Section
License
Copyright (c) 2025 Neutrosophic Sets and Systems

This work is licensed under a Creative Commons Attribution 4.0 International License.






